2. การใช้งาน Apache Spark เพื่อทำ Machine Learning
การติดตั้ง Apache Spark ให้ติดตั้ง Hadoop, Yarn, Hive, Scala, Spark ตามคู่มือที่ได้เขียนเป็นแนวทางไว้ให้ หลังจากติดตั้งแล้วเราจะมาเริ่มต้นเข้าใจหลักการของ Spark
- คำอธิบายของฟังก์ชันใน SparkContext ดูได้ที่นี่ https://spark.apache.org/docs/latest/api/java/org/apache/spark/SparkContext.html
- ตัวอย่างการใช้งาน Scala กับ Eclipse ดูได้ที่นี่ http://www.devinline.com/2016/01/apache-spark-setup-in-eclipse-scala-ide.html เป็นตัวอย่าง WordCount ใช้ Maven เอา Spark Library เข้ามา เขียนเป็นภาษา Scala แต่รันกับ Spark
- วิธีการเขียนโปรแกรมกับ Spark ให้ดูตัวอย่างได้จากที่นี่ https://spark.apache.org/docs/latest/programming-guide.html#linking-with-spark เลือกว่าจะใช้ภาษา Scala, Java หรือ Python
2.1 แพลตฟอร์ม Big Data และ Machine Learning
เราจะจำลองระบบที่ใช้สำหรับเรียนรู้วิชา Machine Learning ตามแพลตฟอร์ม Big Data ตามภาพต่อไปนี้
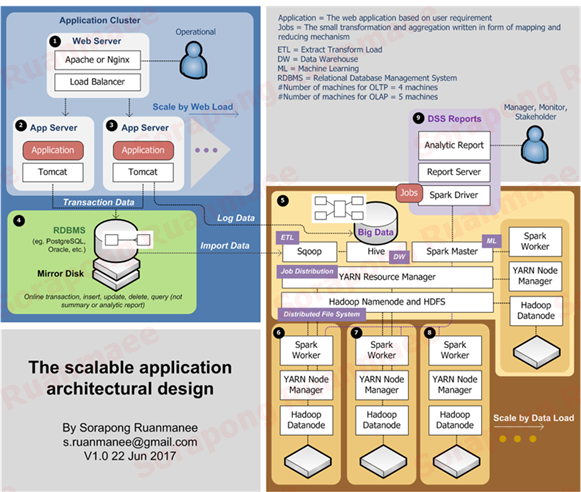
รูปภาพ 9 แพลตฟอร์มของ Big Data แบบ Opensource[1]
[1] ท่านที่สนใจขั้นตอนการติดตั้งและทดสอบระบบ Big Data และ Machine Learning สามารถติดต่อได้ที่ s.ruanmanee@gmail.com
ในภาพนี้ระบบจะประกอบด้วย 2 ส่วนคือส่วนที่เป็น OLTP (Online Transaction Processing) ที่ใช้ดำเนินงานรายวัน เช่น ระบบซื้อ ระบบขาย และระบบธุรกิจอื่นๆในองค์กร อีกส่วนหนึ่งด้านขวามือจะเป็นส่วน OLAP (Online Analytical Processing) เป็นส่วนที่นำข้อมูลมาวิเคราะห์และประมวลผลเพื่อออกรายงานที่ใช้ในการติดตามดูและ (Monitoring Report) หรือรายงานที่ใช้ตัดสินใจในเรื่องสำคัญต่างๆของธุรกิจ (Decision Support System Report)
ระบบที่เป็น Hadoop จะรองรับข้อมูลขนาดใหญ่ได้ตั้งแต่ 100 GB ขึ้นไป และสามารถขยายต่อระบบได้ในกรณีที่ข้อมูลเพิ่มมากขึ้นเรื่อยๆ วิธีการขยายต่อระบบจะทำโดยการเพิ่มเครื่องที่เป็น Worker Node พร้อมกับดิสก์ไดรฟ์ Worker Node จะช่วยลดปัญหาการรอคอยอ่านเขียนดิสก์ เนื่องจากจะทำงานแบบขนาน (Parallel Computing) ในภาพข้างต้น Hadoop จะรับหน้าที่กระจายข้อมูลผ่านทาง HDFS (Hadoop File System) เพื่อให้ข้อมูลพร้อมสำหรับการประมวลผล ส่วน YARN จะทำหน้าที่จัดเรียงคิวและกระจายงานที่เขียนมาแบบ MapReduced ตัว Spark จะช่วยทำ Machine Learning รวมทั้งกระจายข้อมูลในแบบ in-memory ซึ่งแตกต่างกับ Hadoop ที่กระจายแบบเขียนลงดิสก์ พูดง่ายๆ คือ Spark กระจายข้อมูลเพื่อทำงานขนานแต่ข้อมูลกระจายไปบน RAM ของเครื่องที่เป็น Worker Node ส่วน Hadoop กับ YARN กระจายข้อมูลเช่นเดียวกัน แต่ข้อมูลกระจายไปบน Disk Drive ของเครื่องที่เป็น Worker Node
จะเห็นว่าระบบมี Fault Tolerance ด้านข้อมูลค่อนข้างสูง เนื่องจากส่วน OLTP ใช้ Mirror Disk ในการเก็บข้อมูล Database ดังนั้นจึงสามารถกู้คืนระบบได้แม้ว่าดิสก์จะเสีย ในเอกสารนี้จะจัดเตรียมเฉพาะส่วนที่เป็น OLAP ไว้เพื่อใช้สำหรับการทำ Machine Learning เท่านั้น ส่วนของ Sqoop ที่ใช้สำหรับถ่ายโอนข้อมูลจาก OLTP มาที่ OLAP จะยังไม่อยู่ในขอบเขตของการศึกษา
2.2 การติดตั้งระบบสำหรับศึกษา Machine Learning และ Big Data
ให้ติดตั้ง Java (เวอร์ชัน 1.8), Maven, Eclipse (เวอร์ชัน Neon), Hadoop (เวอร์ชัน 2.8.0), Hive (เวอร์ชัน 2.1.0), Spark (เวอร์ชัน 2.1.1), Scala IDE for Eclipse และโปรแกรมช่วยเหลืออื่นๆที่จำเป็น ถ้าท่านได้ติดตั้งโปรแกรมทั้งหมดนี้แล้ว[1] ขั้นตอนการเปิดระบบอย่างย่อๆ ให้ทำดังนี้
- เปิดระบบ Hadoop ส่วน Namenode โดยใช้คำสั่ง hdfs namenode
- เปิดระบบ Hadoop ส่วน Datanode โดยใช้คำสั่ง hdfs datanode เปิดดูระบบที่ http://localhost:50070
ในภาพต่อไปนี้เป็นระบบ Hadoop File System แล้วจะสามารถเปิดเบราเซอร์ไปที่ http://localhost:50070 ได้ดังนี้
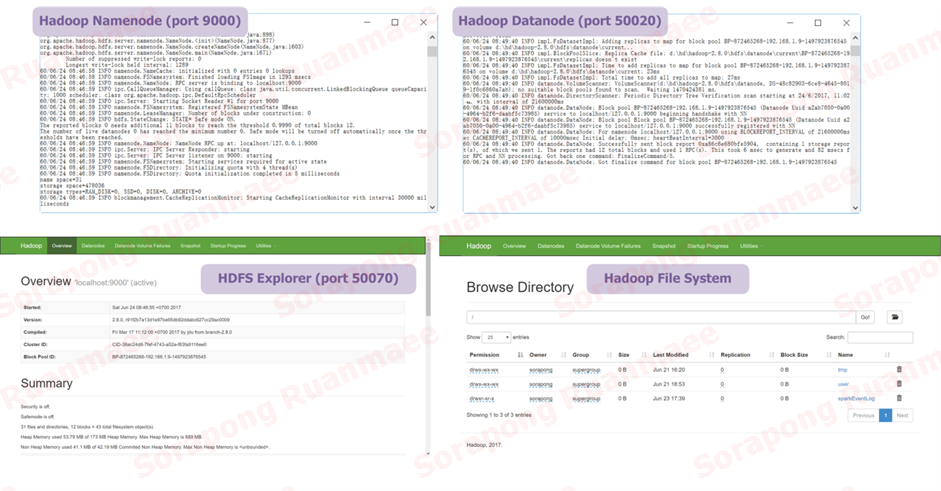
รูปภาพ 10 การเปิดระบบ Hadoop File System
เมื่อเปิด Hadoop แล้วขั้นต่อไปจะเปิดใช้งาน YARN ที่เป็น Job Scheduler ของ MapReduced (เดิมคือ mapred ปัจจุบันเลิกใช้และมาใช้ yarn แทนแล้ว) การสตาทร์ YARN ให้ทำดังนี้
- เปิดระบบ YARN ส่วน Resource Manager โดยใช้คำสั่ง yarn resourcemanager
- เปิดระบบ YARN ส่วน Node Manager โดยใช้คำสั่ง yarn nodemanager เปิดดูระบบที่ http://localhost:8088
เมื่อสตาทร์ YARN ค้างไว้ทั้ง Resource Manager และ Node Manager แล้วจะสามารถเบราซ์ไปที่ http://localhost:8088 และปรากฏภาพดังนี้
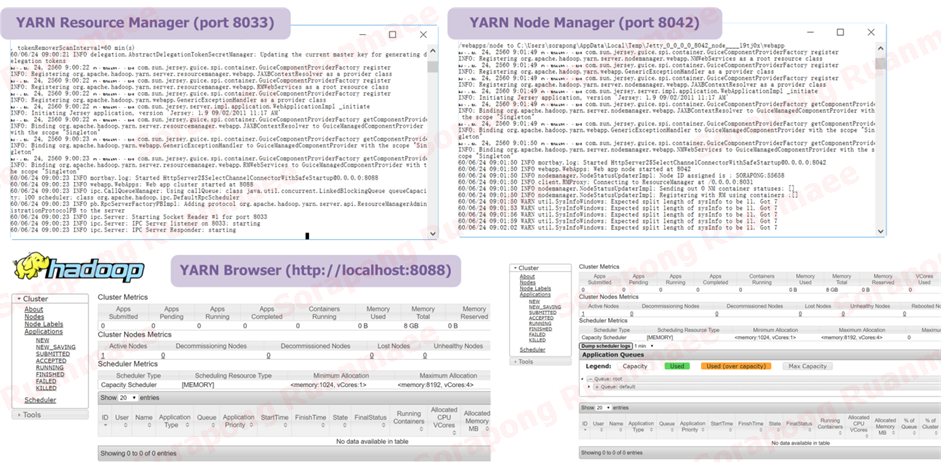
รูปภาพ 11 การเปิดระบบ YARN
เมื่อเปิดระบบ YARN แล้วขั้นต่อไป ท่านสามารถสตาทร์ Hive Server ที่เป็น Data Warehouse สำหรับ Hadoop ได้โดยใช้คำสั่ง hive –service hiveserver2 แล้วเปิดดูฐานข้อมูลได้ผ่านทาง Data Explorer ของ Eclipse ดังภาพต่อไปนี้
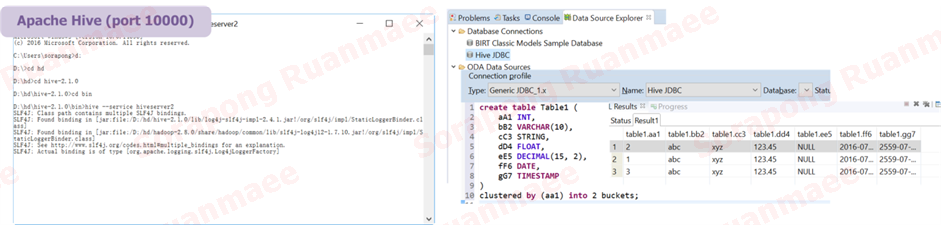
รูปภาพ 12 การเปิดระบบ Hive
หลังจากนั้นให้เปิดระบบ Spark (ใช้เวอร์ชัน 2.1.1) ทั้งตัว Master และตัว Worker รอไว้ โดยใช้คำสั่งต่อไปนี้
- เปิดระบบ Spark ส่วน Master โดยใช้คำสั่ง spark-class org.apache.spark.deploy.master.Master
- เปิดระบบ Spark ส่วน Worker โดยใช้คำสั่ง spark-class org.apache.spark.deploy.worker.Worker spark://127.0.0.1:7077
และทดสอบว่า Spark สามารถใช้งานได้โดยใช้คำสั่ง run-example org.apache.spark.examples.SparkPi ซึ่งจะได้ผลลัพธ์ดังภาพต่อไปนี้
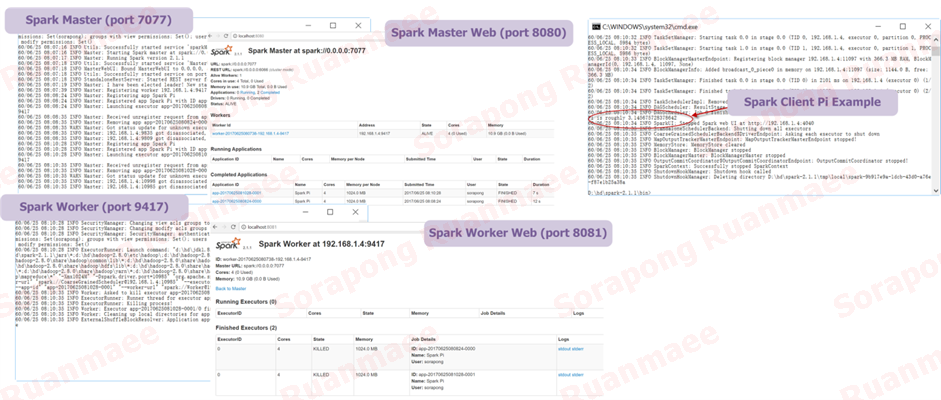
รูปภาพ 13 การเปิดระบบ Spark และรัน Pi Example เพื่อทดสอบระบบ
เราจะได้ระบบ Hadoop, YARN, Hive, Spark ที่พร้อมสำหรับการทดลอง หลังจากนั้นให้จัดเตรียม Eclipse และ Scala IDE for Eclipse เพื่อให้สามารถรันโปรแกรม Spark ในแบบภาษา Scala ผ่านทาง Eclipse ได้ดังนี้
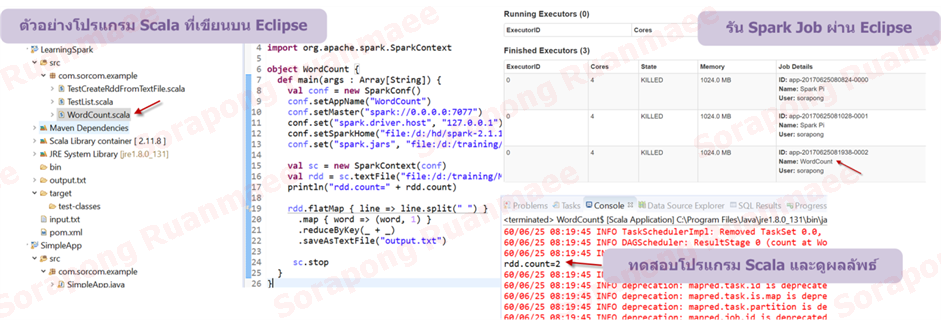
รูปภาพ 14 การเขียนโปรแกรม Scala เพื่อสร้าง Job ไปรันกับ Spark
จะเห็นว่าเราจำเป็นต้องใช้โปรแกรมหลายหลากในการเรียนรู้และทดสอบเรื่อง Machine Learning และ Big Data เนื่องจากผู้เขียนต้องการให้ผู้อ่านสามารถนำไปใช้งานได้จริงในองค์กร ซึ่งคาดหมายว่าจะพัฒนาระบบ Machine Learning ที่ประมวลผลข้อมูลขนาดใหญ่ (ปกติจะใหญ่มากกว่า 100 GB) อย่างไรก็ตามหากว่าผู้อ่านต้องการเรียนรู้ Machine Learning อัลกอริธึมอย่างเดียว เราอาจจะสามารถใช้โปรแกรมขนาดเล็กอย่าง GNU Octave พร้อมกับไฟล์ข้อมูล Data Set จำนวนหนึ่งก็สามารถเรียนรู้ได้เช่นกัน
[1] กรุณาอ่านเพิ่มเติมที่ คู่มือการติดตั้งแพลตฟอร์ม Big Data และ Machine Learning