1.1 Machine Learning คืออะไร
Machine Learning เป็นวิธีการทำให้คอมพิวเตอร์สามารถเรียนรู้และจดจำวิธีการตัดสินใจ เพื่อแก้ปัญหาที่เกิดซ้ำๆและยังไม่มีกฏเกณฑ์ตายตัวในการตัดสินใจ ตัวอย่างของระบบที่เป็น Machine Learning เช่น ระบบรถยนต์ไร้คนขับ ระบบตัดสินใจอนุมัติสินเชื่ออัตโนมัติ ระบบแนะนำสินค้าที่เหมาะสมกับเพศและวัยของลูกค้า ระบบกรองคำหยาบ ระบบแปลภาษา ระบบเกมส์หมากรุก ระบบจำลองเป็นผู้เชี่ยวชาญในศาสตร์สาขาต่างๆ จะเห็นว่า Machine Learning ถูกนำไปใช้แทบจะทุกอย่างที่เลียนแบบวิธีการคิดและตัดสินใจของคน เพื่อให้คอมพิวเตอร์สามารถที่ตัดสินใจได้เองจากข้อมูลรอบด้านที่มีอยู่และได้ผลที่ถูกต้องเช่นเดียวกับที่ให้คนตัดสินใจ
ดังนั้นผู้พัฒนาระบบ Machine Learning จะสร้างระบบได้โดยทำ 2 ขั้นตอนพื้นฐานคือ ขั้นแรกคือการเรียนรู้ โดยจะนำเอาข้อมูลเก่ามาฝึกฝน (Training) คอมพิวเตอร์เพื่อให้คอมพิวเตอร์เรียนรู้และและจดจำรูปแบบ (Pattern) ผลลัพธ์ของขั้นตอนแรกก็คือตัวแบบโมเดล (Model) ที่ใช้สำหรับพยากรณ์หรือตัดสินใจ เมื่อผ่านขั้นตอนเรียนรู้แล้ว ขั้นที่สองจะเป็นการพยากรณ์และตัดสินใจ (Predict) โดยขณะที่เกิดเหตุการณ์และมีข้อมูลปัจจุบันเข้าสู่ระบบ คอมพิวเตอร์จะอาศัยตัวแบบโมเดลที่จดจำไว้แล้วจากการเรียนรู้ นำมาใช้กับข้อมูลปัจจุบันแบบเรียลไทม์ (Realtime) และตัดสินใจดำเนินการอะไรบางอย่าง ผลลัพธ์ที่ได้จะทำให้ผู้ใช้เห็นว่าระบบสามารถทำงานบางอย่างได้ใกล้เคียงกับคน
1.2 กระบวนการ Machine Learning
ต่อไปนี้เป็นภาพกระบวนการแบบง่ายๆของ Machine Learning
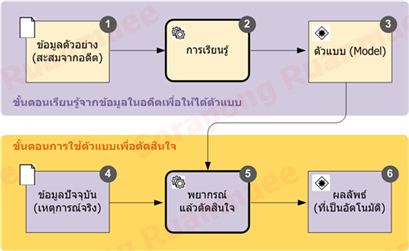
รูปภาพ 1 กระบวนการ Machine Learning
ในภาพข้างต้นจะเห็นว่าผลลัพธ์ที่ต้องการจากขั้นตอนเรียนรู้คือตัวแบบ Model เพื่อที่จะนำมาใช้ในขั้นตอนพยากรณ์แล้วตัดสินใจ (หมายเลข 5) ในภาพข้างต้น ขั้นตอนการเรียนรู้จากข้อมูลตัวอย่างในอดีตเป็นขั้นตอนที่กินเวลาและใช้ทรัพยากรคอมพิวเตอร์ค่อนข้างมาก ขึ้นอยู่กับจำนวนฟีเจอร์ (Feature หรือบางทีเรียกว่าตัวแปร) จำนวนแถวข้อมูล (ก็คือจำนวนตัวอย่างที่สุ่มมา) และขึ้นอยู่กับกรรมวิธีการเรียนรู้ (อัลกอริธึมที่ใช้ประมวลผลข้อมูลเพื่อสร้างตัวแบบ) ในขั้นตอนนี้บางครั้งอาจจะกินเวลาตั้งแต่ 1 วันถึงหลายเดือน แต่อัลกอริธึมส่วนใหญ่จะทำงานได้อย่างรวดเร็วในขั้นตอนพยากรณ์และตัดสินใจ เนื่องจากเป็นเพียงสูตรทางคณิตศาสตร์เท่านั้น เมื่อแทนที่ตัวแปรด้วยค่าจริงก็จะได้ผลลัพธ์ออกมา ซึ่งขั้นตอนนี้คอมพิวเตอร์ใช้เวลาเพียงแค่เสี้ยววินาทีเท่านั้นเอง
1.3 ประเภทของตัวแบบอัลกอริธึมใน Machine Learning
อัลกอริธึมทั้งหมดใน Machine Learning มีเป้าหมายเพื่อสร้างโมเดลทางคณิตศาสตร์ (Mathematic Model) จากข้อมูลตัวอย่าง (Sample Data) ดังนั้น เราจะพบว่าโมเดลที่ใช้บ่อยจะมาจากวิชาสถิติและความน่าจะเป็น เนื่องจากเป็นวิชาที่ว่าด้วยการย้อนรอยข้อมูลในอดีตและวิเคราะห์ข้อมูลอย่างเป็นระบบเพื่อให้สามารถพยากรณ์อนาคตได้
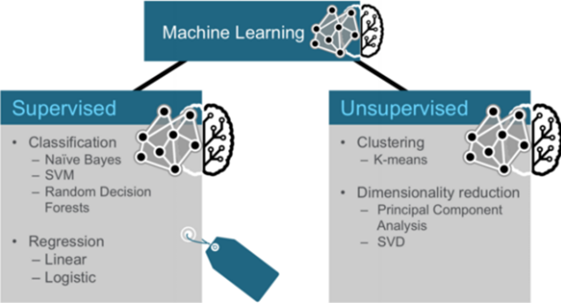
รูปภาพ 2 ประเภทของอัลกอริธึม Machine Learning[1]
ในภาพข้างต้นจะเห็นว่าอัลกอริธึมแบ่งออกเป็น 2 ประเภทใหญ่ๆคือ Supervised และ Unsupervised ซึ่งมีความหมายคือ
[1] ที่มาจาก https://mapr.com/blog/apache-spark-machine-learning-tutorial/
1.3.1 ความหมายของ Supervised และ Unsupervised Learning
คำศัพท์ทั้ง 2 คำนี้ใช้ในวิชา Machine Learning, Data Mining และ Pattern Recognition ใช้แยกลักษณะของอัลกอริธึมที่เรียนรู้จากข้อมูลตัวอย่าง โดยแบ่งอัลกอริธึมออกเป็น 2 แบบ มีความหมายแต่ละแบบดังนี้
p Supervised เป็นการเรียนรู้โดยให้ทั้งโจทย์และเฉลย หน้าที่ของอัลกอริธึมคือพยายามสร้างโมเดลที่สามารถจับคู่โจทย์เข้ากับเฉลยโดยให้มีความคลาดเคลื่อน (Error) น้อยสุด ดังนั้นจึงเรียกอัลกอริธึมแนวนี้ว่าเป็น Supervised ที่แปลว่า “แนะแนว” เพราะผู้ใช้อัลกอริธึมแบบนี้จะมีคำตอบรอไว้ให้กับทุกข้อที่เป็นข้อมูลตัวอย่างอยู่แล้ว และถ้าให้คอมพิวเตอร์ช่วยตอบ ก็สามารถบอกได้ทันทีว่าคำตอบของคอมพิวเตอร์เป็นคำตอบที่ถูกหรือผิด
p Unsupervised เป็นการเรียนรู้โดยให้แต่โจทย์แต่ไม่รู้เฉลย ลักษณะโมเดลที่ได้ ไม่สามารถบอกได้ว่าถูกหรือผิด ตัวอย่างเช่น การแบ่งกลุ่ม (Clustering) การวิเคราะห์โครงข่าย (Social Network Analysis) เมื่อดูจากผลการวิเคราะห์ ผู้อ่านรายงานก็ไม่สามารถบอกได้เช่นกันว่าถูกหรือผิดอย่างไร และจำเป็นต้องนำไปขยายความต่อไป อัลกอริธึมแบบนี้จึงเรียกว่าเป็น Unsupervised นั่นคือไม่ต้องมีการแนะคำตอบถูกให้อัลกอริธึม เพราะโดยตัวอัลกอริธึมเองไม่ได้สนใจ
ในหัวข้อถัดไปจะยกตัวอย่างให้เห็นว่าเราจะเอาอัลกอริธึมแต่ละแบบไปใช้งานอะไรได้บ้าง
1.3.2 Supervised Learning
อัลกอริธึมแบบนี้ ต้องการทั้งตัวอย่างข้อมูล และคำตอบ (ตั้งธงไว้แล้ว) ที่เป็นคำตอบที่ถูก ตัวอย่างเช่น ถ้าให้คอมพิวเตอร์ช่วยรู้จำสีของรถยนต์ (Color Recognition) เราจะมีชุดของข้อมูลตัวอย่างที่เราเองก็บอกได้อยู่แล้วว่ารถคันนั้นเป็นสีอะไร เมื่อนำข้อมูลชุดนี้ไปใช้สำหรับเทรน (Train) คอมพิวเตอร์ เมื่อเทรนเสร็จแล้ว เราจะทดสอบโดยให้คอมพิวเตอร์ตอบว่ารถยนต์คันที่เข้ามาใหม่นี้เป็นสีอะไรบ้าง คำตอบที่คอมพิวเตอร์ตอบมา เราสามารถบอกได้ทันทีว่าถูกหรือผิด (เพราะการแยกแยะสีเป็นความสามารถหนึ่งของมนุษย์อยู่แล้ว) ถ้าคอมพิวเตอร์ตอบได้ถูกต้องทั้งหมดนั่นแสดงว่าเราสามารถสร้างระบบคอมพิวเตอร์ที่รู้จำสีได้อย่างสมบูรณ์
1.3.3 Classification
จะเห็นว่างานที่นำเอา Supervised Learning มาใช้ส่วนใหญ่จะเป็นการแยกแยะ (Classification) ประเภทของข้อมูล เช่น การแยกแยะสีรถ การตรวจสอบอีเมล์ขยะ การตรวจสอบโรคมะเร็งว่าเป็นหรือไม่เป็น
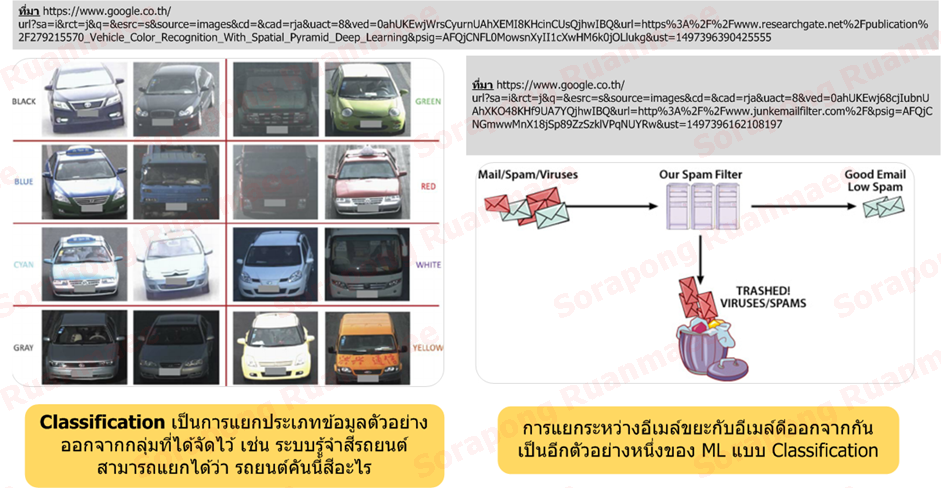
รูปภาพ 3 ตัวอย่างของ Classification (การแยกประเภท)
ตัวอย่างของอัลกอริธึมแบบ Classification เช่น SVM (Support Vector Machine), Naïve Bay, Decision Tree เป็นต้น
1.3.4 Regression
Regression เป็นอัลกอริธึมแบบ Supervised Learning แต่ไม่ได้ใช้แยกประเภทหมวดหมู่ Regression ให้คำตอบเป็นค่าพยากรณ์ที่เป็นเลขทศนิยมเช่น ราคาที่ดินในอีก 5 ปีข้างหน้า ราคาบ้านโดยประเมินจากปัจจัยรอบด้าน ราคารถที่ประเมินจากปัจจัยรอบด้าน เป็นต้น

รูปภาพ 4 ตัวอย่างของ Regression
จะเห็นว่าโมเดลในการทำ Regression จะมีทั้งแบบ Linear และ Non-Linear แบบ Linear จะใช้เยอะสุดเนื่องจากคำนวณง่ายและให้คำตอบที่พอเหมาะเป็นกลางๆไม่ดีและไม่แย่เกินไปนัก ท่านอาจจะเคยเรียนรู้เกี่ยวกับ Regression มาแล้วจากวิชาสถิติ แต่สำหรับ Machine Learning ส่วนใหญ่จะเป็น Regression ที่มีตัวแปรมากกว่า 1 ตัว หรือที่เราเรียกว่าเป็น Multi-variable Regression เพื่อให้สามารถพยากรณ์ค่าผลลัพธ์ได้จากหลายปัจจัยนั่นเอง
นอกจาก Linear Regression และ Non-Linear แล้ว ยังมี Regression อีกแบบหนึ่งที่เรียกว่าเป็น Logistic Regression (มาจากคำว่า Logit ในทางคณิตศาสตร์ ซึ่งหมายถึง Inverse ของ Sigmoid Function ไม่เกี่ยวอะไรกับ Logistic ในที่แปลว่าการขนส่ง)
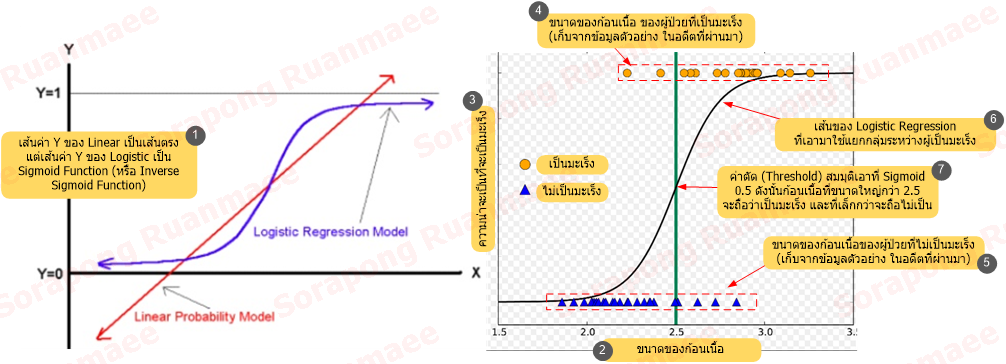
รูปภาพ 5 ตัวอย่างของ Logistic Regression
Logistic Regression ใช้ Sigmoid Function เป็นแนวเส้นกำกับ แทนที่จะเป็นเส้นแบบ Linear ทำให้ได้คำตอบออกมา โดยแยกข้อมูลออกเป็น 2 กลุ่มคือ กลุ่มที่ค่าน้อยกว่าค่าตัด (Threshold Value) และกลุ่มที่ค่ามากกว่าค่าตัด การแยกของออกเป็น 2 กลุ่มส่วนใหญ่จะต้องใช้ Logistic Regression ทั้งหมด
1.3.5 Clustering
การแบ่งกลุ่มด้วยวิธีการ Clustering เป็นอัลกอริธึมแบบ Unsupervised Learning เนื่องจากผู้ให้ข้อมูลจะไม่มีคำตอบ (หรือไม่ควรจะมีคำตอบแบบตั้งธงไว้) ที่ชัดเจนว่ามีกี่กลุ่ม กลุ่มอะไรบ้าง
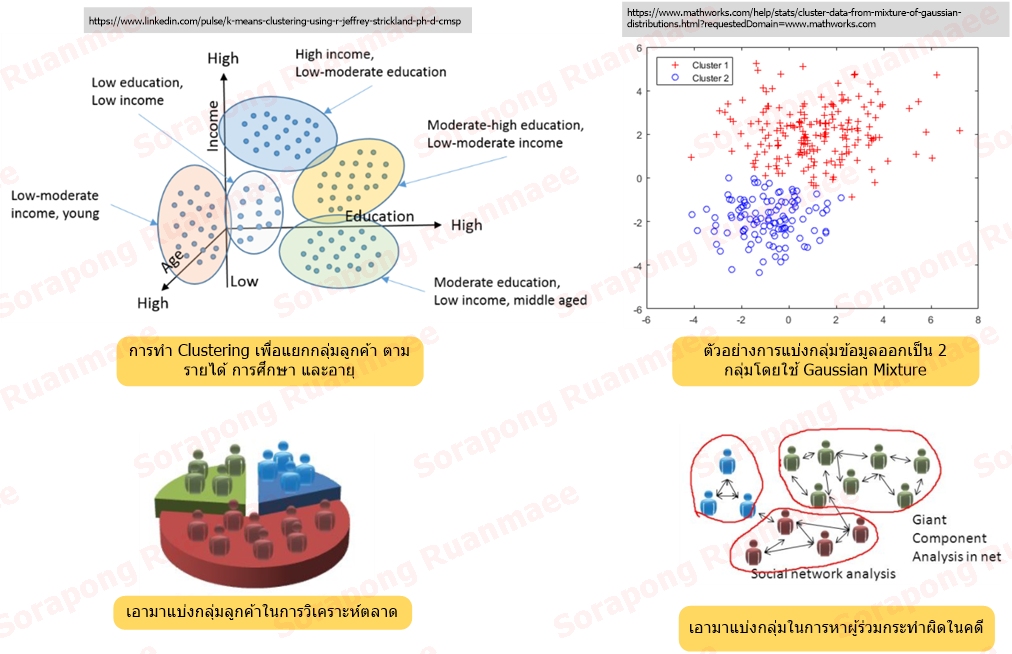
รูปภาพ 6 ตัวอย่างของ Clustering
อัลกอริธึมที่มักจะถูกนำมาใช้ทำ Cluster เช่น K-Means หรือ Gaussian Mixture เป็นต้น ลักษณะอัลกอริธึมจะเป็นการวนทำไปเรื่อยๆ โดยการขยับจุดกึ่งกลาง (Centroid) ให้เข้าสู่ค่ากลาง (Average Point) ซึ่งจะคำนวณค่ากลางจากระยะทาง (Distance) ที่ห่างจากจุดกึ่งกลาง ทำซ้ำไปเรื่อยๆจนในที่สุดทุกตัวที่อยู่ในกลุ่มจะมีค่าความคลาดเคลื่อนจากค่ากลางต่ำสุดเมื่อเทียบกับการย้ายไปอยู่กลุ่มอื่น
1.3.6 Dimensional Reduction
เป็นวิธีการลดตัวแปรที่ไม่จำเป็นต่อผลลัพธ์ออกไป เพื่อช่วยการคำนวณทำได้เร็วขึ้น และเพื่อปรับปรุงให้คำตอบของคอมพิวเตอร์ถูกต้องมากยิ่งขึ้น ตัวอย่างเช่น การพยากรณ์ราคาบ้าน อาจจะมีตัวแปรคือ ตำแหน่งที่ตั้ง ขนาดพื้นที่ใช้สอย จำนวนห้องนอน จำนวนห้องน้ำ โรงจอดรถ สนามหญ้า สระว่ายน้ำ อายุของบ้าน ซึ่งจะพบว่าอาจจะมีตัวแปรเยอะมาก แต่เมื่อนำมาพยากรณ์จริงๆพบว่าตัวแปรที่มีอิทธิพลสูงต่อราคาบ้านมีแค่ 2 ตัวคือ ตำแหน่งที่ตั้งและขนาดพื้นที่ใช้สอยเท่านั้น ส่วนตัวแปรอื่นๆแทบจะไม่มีอิทธิพลเลย
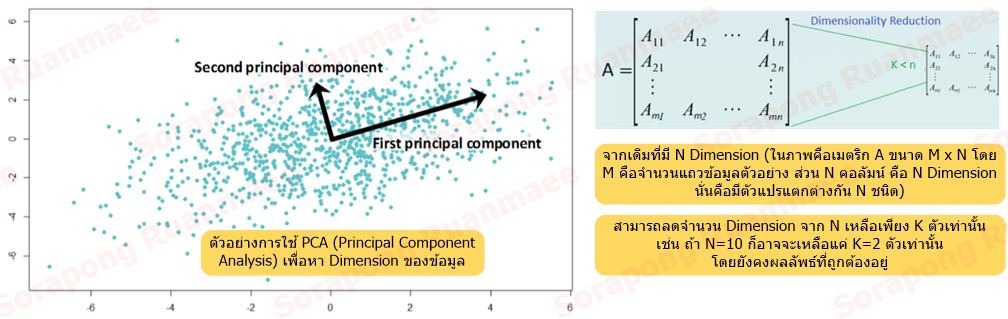
รูปภาพ 7 ตัวอย่างของ Dimensional Reduction
ในคำถามที่คนสามารถใช้ดุลพินิจในการตัดสินใจได้ เช่น เรื่องของราคาบ้าน เราตัดสินใจได้จากประสบการณ์ว่ามีแค่ 2 ตัวแปรเท่านั้นที่มีอิทธิพลสูง แต่ในคำถามที่ซับซ้อนเราอาจจะไม่รู้ถึงปัจจัยจริงที่มีอิทธิพลต่อคำตอบ ตัวอย่างเช่นการตรวจผลิตภัณฑ์ที่ไม่ได้คุณภาพ และปัจจัยที่ทำให้ไม่ได้คุณภาพ ซึ่งเราอาจจะตัดสินใจไม่ได้ว่าปัจจัยไหนกันแน่ที่มีอิทธิพลน้อยต่อการด้อยคุณภาพของสินค้า อัลกอริธึมในกลุ่ม Dimensional Reduction จะช่วยวิเคราะห์ความแรงของตัวแปรต่อผลลัพธ์เพื่อให้เราสามารถตัดทอนตัวแปรที่ไม่แรงออกไปได้
1.4 เครื่องมือที่ใช้ในการทำ Machine Learning
เครื่องมือที่ใช้ในการทำ Machine Learning แบ่งออกเป็นกลุ่มได้หลายแบบ
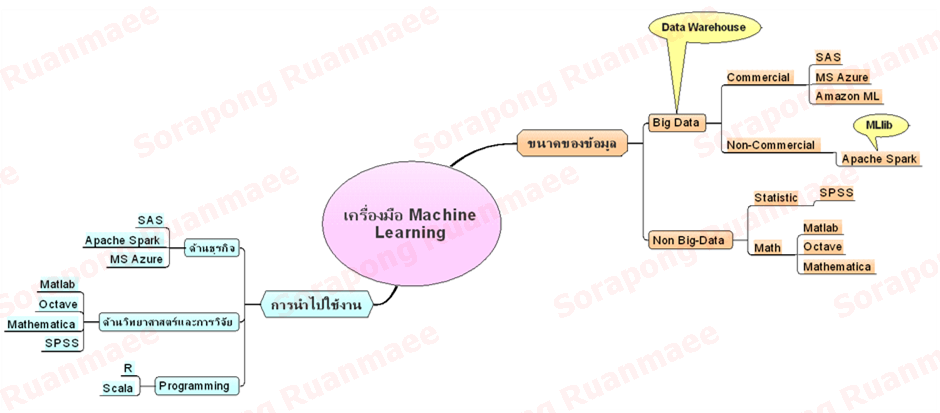
รูปภาพ 8 เครื่องมือสำหรับการทำ Machine Learning
เครื่องมือที่ใช้ทำ Machine Learning จะผสมปนเปกันระหว่างงานสายวิทยาศาสตร์ สถิติ งานวิจัย ซึ่งเดิมเครื่องมือที่นิยมใช้ในกลุ่มนี้จะเป็น SPSS หรือ Matlab แต่เนื่องจากปัจจุบันมีการนำเอาข้อมูลขนาดใหญ่มาก (ขนาดตั้งแต่ 1 ล้านตัวไปจนถึง ล้านล้านตัว) มาวิเคราะห์เพื่อหาโมเดลตามแบบของ Machine Learning ซึ่งพบว่าเครื่องมือยุคดั้งเดิมจะทำงานได้ช้าเมื่อเล่นกับข้อมูลขนาดใหญ่ ดังนั้น จึงมีกลุ่มเครื่องมืออีกกลุ่มนึงที่เน้นเรื่องการทำ ML กับข้อมูลขนาดใหญ่โดยเฉพาะเช่น SAS หรือ Apache Spark เป็นต้น
1.5 สรุปก่อนเริ่มลงมือทำ
จากที่ได้ศึกษามาท่านจะเห็นแล้วว่า Machine Learning แบ่งออกเป็น Supervised หรือ Unsupervised Learning ผู้ที่จะนำมาใช้งานจะต้องเลือกอัลกอริธึมที่เหมาะสมกับงานของตนเอง นอกจากนี้ยังต้องเลือกเครื่องมือที่มีอยู่ในปัจจุบันให้ตรงกับองค์ความรู้ของทีมงานไอทีที่บริษัทท่านมีอยู่ด้วยจึงจะสามารถบำรุงรักษาระบบ Machine Learning ให้ทำงานได้ต่อไป ในหัวข้อถัดไป เราจะนำเอา Apache Spark และ R มาใช้ในการทำ Classification, Regression และ Clustering สาเหตุที่เลือก 2 ตัวนี้เนื่องจากเป็น Non-Commercial ที่มีผู้ใช้งานเยอะ มีเอกสารประกอบ ทำให้สามารถศึกษาและนำไปประยุกต์ใช้ในบริษัทองค์กรของท่านได้ทันที
รอติดตามตอนที่ 2 ครับ